

Disaster Recovery (DR) refers to the process of "preparing for" or "recovering after" a disaster. In this article, we will attempt to describe the Disaster Recovery scenarios and alternatives available on the public cloud - specifically AWS. When creating fault-tolerant, highly available AWS solution designs, we must have a high-level grasp of these alternatives.
Let's first understand what is RTO and RPO with respect to Disaster recovery
RTO (Recovery Time Objective) - This represents the amount of time required to recover after a calamity (restoring a business process to its service level, as defined by the Operational Level Agreement).
For example, if a disaster strikes at 12:00PM (Noon) and the RTO is four (04) hours, the DR procedure should have the system back up and running by 4:00PM.
RTOs are frequently challenging since they involve the restoration of all IT functions. By automating as much as possible, your IT department can help to speed up the recovery process. The RTO may be more expensive than a granular RPO, and a demanding RTO includes your complete company infrastructure, not just data. The expense of achieving an RTO or RPO is proportional to your IT department's application and data priorities. IT ranks applications and data based on income and risk. If the data in an application is regulated, data loss from that app could result in substantial fines regardless of how frequently that app is used.
RPO (Recovery Point Objective) - RPO is the maximum quantity of data that an organization may tolerate losing.
For example, if a disaster strikes at 12:00 PM (Noon) and the RPO is one hour, the system should recover all data stored in the system prior to 11:00 AM. This indicates that the total data loss is only one hour, between 11:00 a.m. and 12:00 p.m. (Noon).

DR Scenarios -
Active - Active
Warm Standby
Pilot Light
Backup-Restore

Active-Active has the lowest RTO while Backup and Recovery has the highest RTO among these four scenarios.
Now, let's have a better understanding of these DR Scenarios mentioned above.
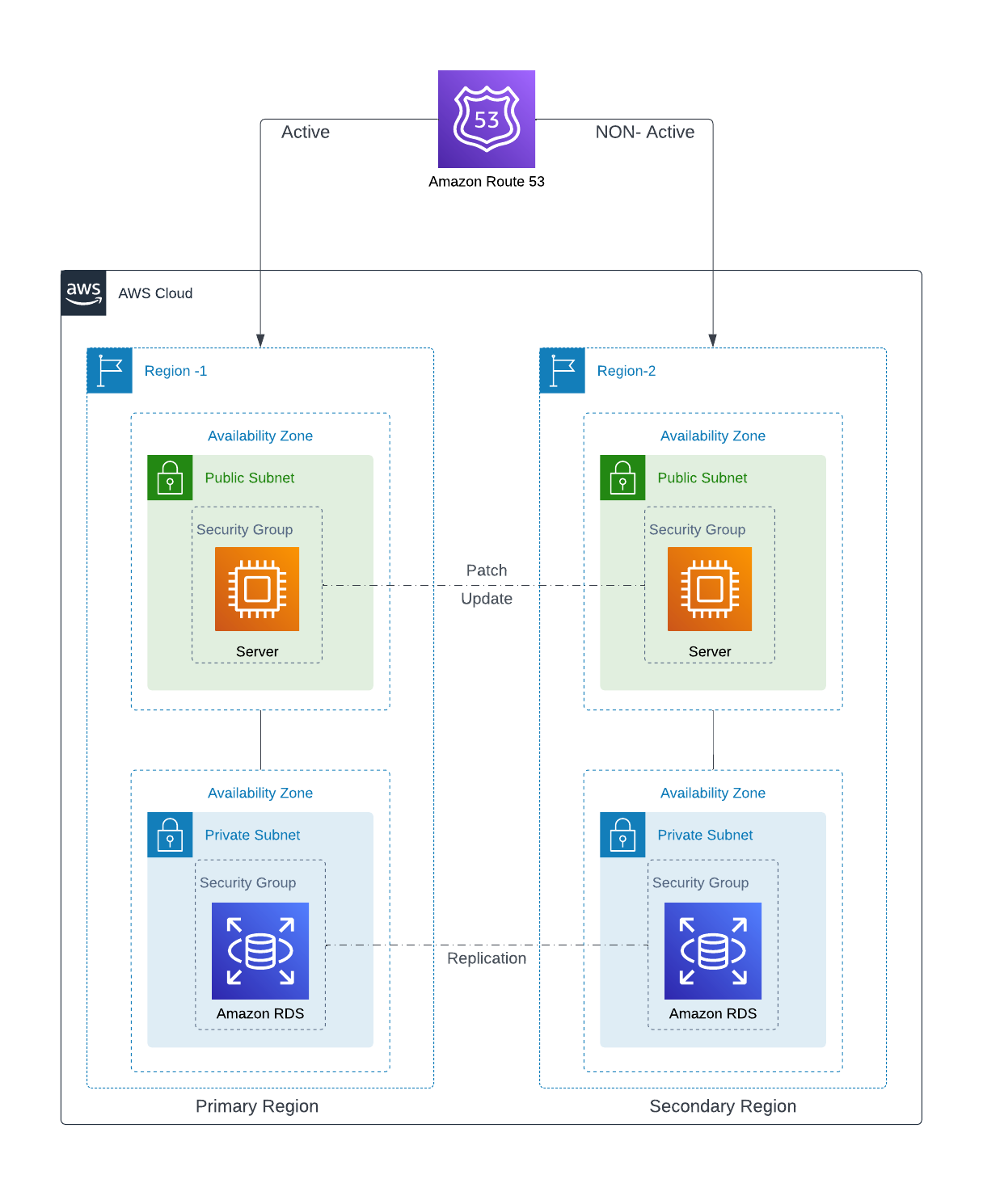
1. Active-active - The secondary backup infrastructure is a replica of the original site's structure, size, and services. This allows you to provide you the highest performance, high availability, and recovery time when compared to the other DR scenarios described. The cost, however, is exactly double that of the major infrastructure.
In an AWS multi-region system, the Active-Active state can provide not just fail-over but also load balancing. We may utilize Route 53 and the Weighted Routing Policy to balance the load.
When a disaster strikes or if the whole region fails, Route 53 will direct all traffic to the secondary site. There is no requirement for infrastructure scaling because both primary and secondary were running at full capacity prior to the tragedy.

2. Warm Standby - The secondary environment uses the same infrastructure as the major one, but with lesser components to save cost. If the primary infrastructure has an extra large EC2 instance, the secondary location would have a medium size EC2 instance.
When a disaster happens, the smaller version(s) may be immediately ramped up to provide an infrastructure identical to the larger one in less time than the Pilot Light technique.
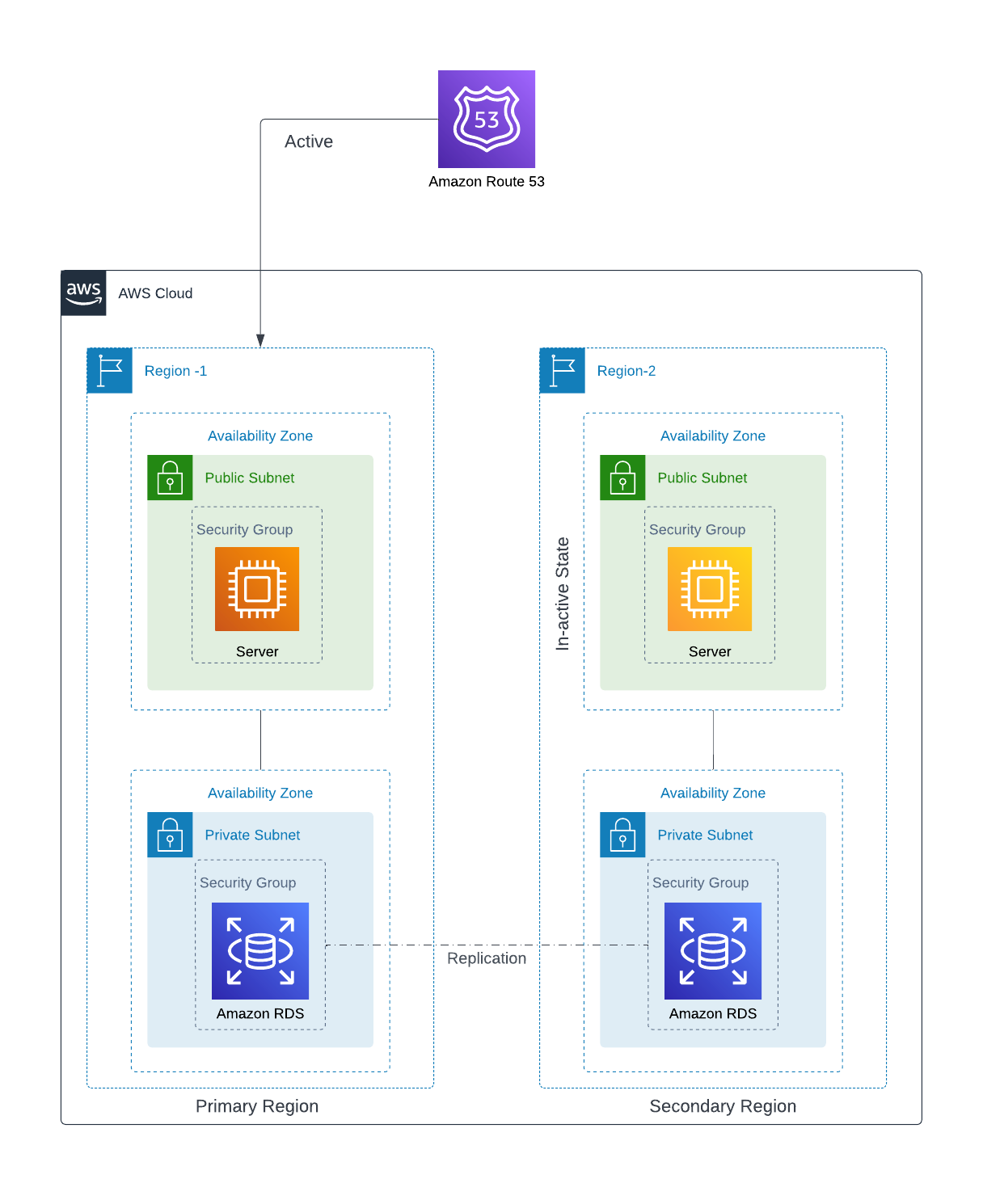
3. Pilot Light - Only the most important core infrastructure is run in the secondary environment. When it's time to recover, you may quickly provision a full-scale production environment around the key core.
Because the fundamental elements of the system are already functioning and are constantly maintained up to date, the pilot light technique provides a faster recovery time than the backup-restore method.
The database is operational in given Figure , but the Application Server is not.
You can use one of the following techniques to restore dormant components and scale up operating components:
Launch your EC2 instances from any modified AMIs.
If necessary, scale up database instances. Add any fail-over functionality to both dormant and active components (Multi-AZ, etc)
Set the Route 53 DNS to point to the secondary site.
4. Backup-Restore - In the AWS ecosystem, there are 5 options available for applying backup-restore strategies.
Amazon S3 – Amazon S3 is an excellent place for backup data that may be required shortly for a restore.
Amazon Storage Gateway – Allows you to backup your on-premise data volumes by transparently copying snapshots into S3. Cached volumes allow you to store primary data on S3 while keeping frequently requested data local for low-latency access. VTL backup can be utilised in place of typical magnetic tape backup.
Amazon Glacier — Glacier may be used with S3 to provide a tiered "long-term" backup solution.
Amazon Import / Export – This feature allows you to transfer very big data sets by delivering storage devices straight to AWS.
When it comes to recovering data from EC2 instances, a mix of the following methods can be used.
Restoring data from S3
Provisioning the instances from an AMI
Comparison between listed Strategies:
Active-Active: Expensive (costs twice as much), yet recovery is faster than any other DR scenarios (near nil recovery time / RTO).
Warm Standby is more expensive, but it recovers faster than "Pilot Light."
Pilot Light: Less expensive, but recovers faster than "Backup and Recovery."
Backup and Recovery: Low cost, but recovery is slow (High RTO)
To Conclude…
Choosing a DR scenario among the ones described above is solely based on the criticality and expense of the system under consideration. As previously stated, the Active-Active strategy provides the best RTO at a significant expense. If money is a critical consideration, you can select one of the other three alternatives offered.

No comments:
Post a Comment