
%20(8).png)
Imagine having tons of documents and needing answers fast. Instead of scrolling forever, what if you had a smart assistant that read everything and gave you the exact answer in seconds?
That’s what ContextQ does. It’s a clean, production-ready RAG system built with Amazon Bedrock, Weaviate, Lambda, and Node.js.
Just upload your files, and ContextQ stores them smartly. Then you can ask questions in plain English and get instant, accurate answers.
No clutter. No confusion. Just your data, working smarter.
How ContextQ Works Behind the Scenes
ContextQ may look simple on the outside, but there’s a lot of smart tech working together behind the scenes. Think of it like a well-oiled machine, with each part doing its job to make everything run smoothly.
Here’s what it’s built with:
- Node.js + Express handle the APIs, making sure your questions and answers go to the right place.
- Amazon S3 + Lambda take care of uploading and preparing your documents.
- Amazon Titan Embedding Model (v2) creates smart embeddings and powers the AI that gives answers.
- Weaviate stores the embeddings for fast and accurate search.
- MySQL + Sequelize keep track of the uploaded content (user login coming soon!).
- Vite + React + ShadCN UI make the app look nice and run smoothly.
Let’s say you upload a bunch of training manuals to ContextQ. It stores them smartly using Weaviate and Bedrock, so later when you ask, “What are the safety rules for lab work?”, it instantly finds the right answer and shows it. All of this happens smoothly behind the scenes, like magic but powered by clean code and cloud tools.
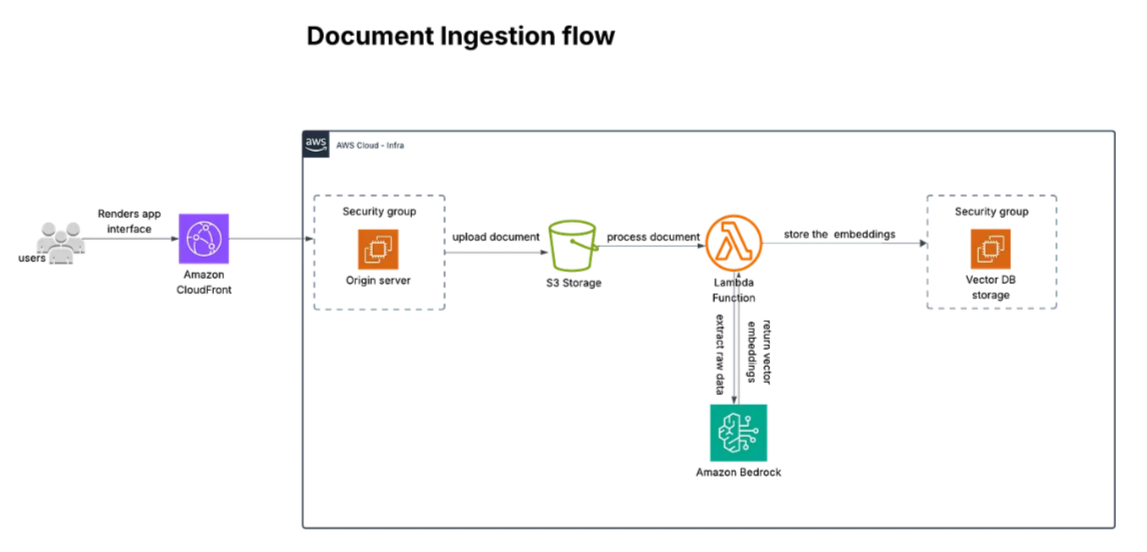
Architecture Overview: How ContextQ Works
Before we jump into the code, let’s see how the whole pipeline flows from document upload to getting a smart GenAI answer. ContextQ connects the dots using AWS tools and open-source magic.
Step-by-Step: From Upload to AI Answer
1. Upload Your Document
You upload a PDF, DOCX, or TXT file using the frontend. Simple!
2. Stored in S3 and Wake Up Lambda
The file goes into an S3 bucket. That storage event wakes up a Lambda function—like saying, "Hey, time to process this file!"
3. Lambda Gets to Work
Lambda now:
- Pulls text from your document
- Breaks it into smaller chunks
- Sends each chunk to Amazon Titan to turn it into smart vector embeddings
- Saves those embeddings in Weaviate, along with file details
4. User Asks a Question
When you type a question, here’s what happens behind the scenes:
- Your question is also turned into an embedding by Amazon Titan
- A quick search is done in Weaviate to find the most relevant document chunks
- Those chunks are added to a smart prompt
- That prompt goes to an LLM in Amazon Bedrock to generate a clear, accurate answer
Document Ingestion: Fully Automated
After you upload a document, everything else just works automatically. The system pulls, chunks, stores, and gets ready to answer your questions. You don’t have to lift a finger.
{
"context_id": "FIN_XYZ",
"context_name": "Finance-Compliance",
"context_type": "policy_doc"
}
That’s it, your document is now ready for smart, meaning based search.
From Question to Answer: How ContextQ Thinks
So, what actually happens when a user types in a question? Let’s break it down in the simplest way:
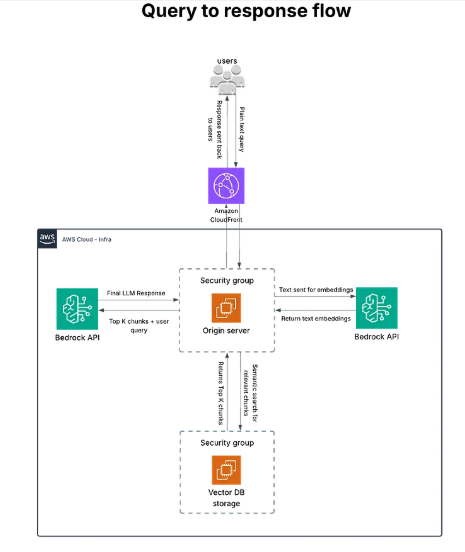
The system first "understands" the question.
It turns your question into an embedding using Amazon Titan, just like how it processed the document chunks earlier.
1. It goes searching!
The system checks Weaviate, our smart storage, to find the top matching chunks of text based on meaning, not just keywords. It filters the results using a unique context ID so you only get relevant info.
2. It builds a smart prompt.
Now it prepares something like this:
yaml
CopyEdit
Context:
Chunk 1: ...
Chunk 2: ...
Question:
How does the leave policy work?
Instructions:
Only use the context above. If not present, reply: “I don’t know based on the provided context.”
3. LLM time!
This prompt is sent to an LLM (like Claude or LLaMA) via the Amazon Bedrock API. The model then replies with a grounded, accurate, and fast answer.
4. Here’s Your Answer With the Right Context
You see the answer on screen, backed by the context from your own documents.
A Simple Yet Smart Frontend
ContextQ comes with a neat and minimal interface, just enough to test the magic end to end. Here's what powers it:
- React + Vite make development fast and the experience smooth
- ShadCN UI provides clean and accessible components (thanks to Tailwind under the hood)
- The interface lets users:
It’s lightweight, elegant, and easy to build on, perfect for developers, teams, or anyone exploring GenAI.
Environment Config Made Easy
ContextQ uses a simple .env file to manage all key settings, so you can adjust things like model choice or search behavior without touching the code. For example, to make your chatbot more creative, just increase the GEN_TEMP value. No need to change any backend code.
TOP_K= VECTOR_CERTAINTY= GEN_TEMP= GEN_TOP_P= LLM_MODEL_ID=<your-llm-model-id> EMBEDDING_MODEL_ID=<your-embedding-model-id> WEAVIATE_URL=http://<weaviate-host>:<your-port-number> BUCKET_NAME=<your-source-bucket>
With this setup, you can easily change and improve things to fit your needs without touching the backend code. Let me know if you'd like this as a checklist or setup guide too! Let ContextQ Do the Work And that’s ContextQ in action! From uploading files to getting instant, accurate answers, everything runs smoothly behind the scenes. You don’t need to write complex code or dig through endless documents. Just plug it in, ask your questions, and boom, answers appear like magic.
Simple setup, smart results, and zero headaches. Now go ahead, upload your docs and let ContextQ do the thinking for you! Contact us today at sales@cloud.in / +91 20-6608 0123
The Blog is written by Atharva Jagtap (Junior Developer, Cloud.in)
.png)
No comments:
Post a Comment